
Los rastreadores de Perplexity seguían accediendo al contenido de decenas de miles de sitios web incluso después de que esos sitios los bloquearon explícitamente, según el proveedor de infraestructura de Internet Cloudflare. La compañía dijo el lunes que había eliminado la perplejidad de su programa BOT verificado e implementó bloques contra lo que caracterizó como prácticas de raspado engañosas.
La perplejidad, con sede en San Francisco, fue fundada en 2022 por Aravind Srinivas (CEO, ex investigador de Operai), Denis Yarats (ex IA de Facebook), Johnny Ho y Andy Konwinski (cofundadores de Databricks). La compañía ha recibido fondos de inversores como Elad Gil, Nat Friedman (ex CEO de Github) y Nvidia, entre otros, y fue valorado en $ 18 mil millones después de recaudar $ 100 millones el mes pasado.
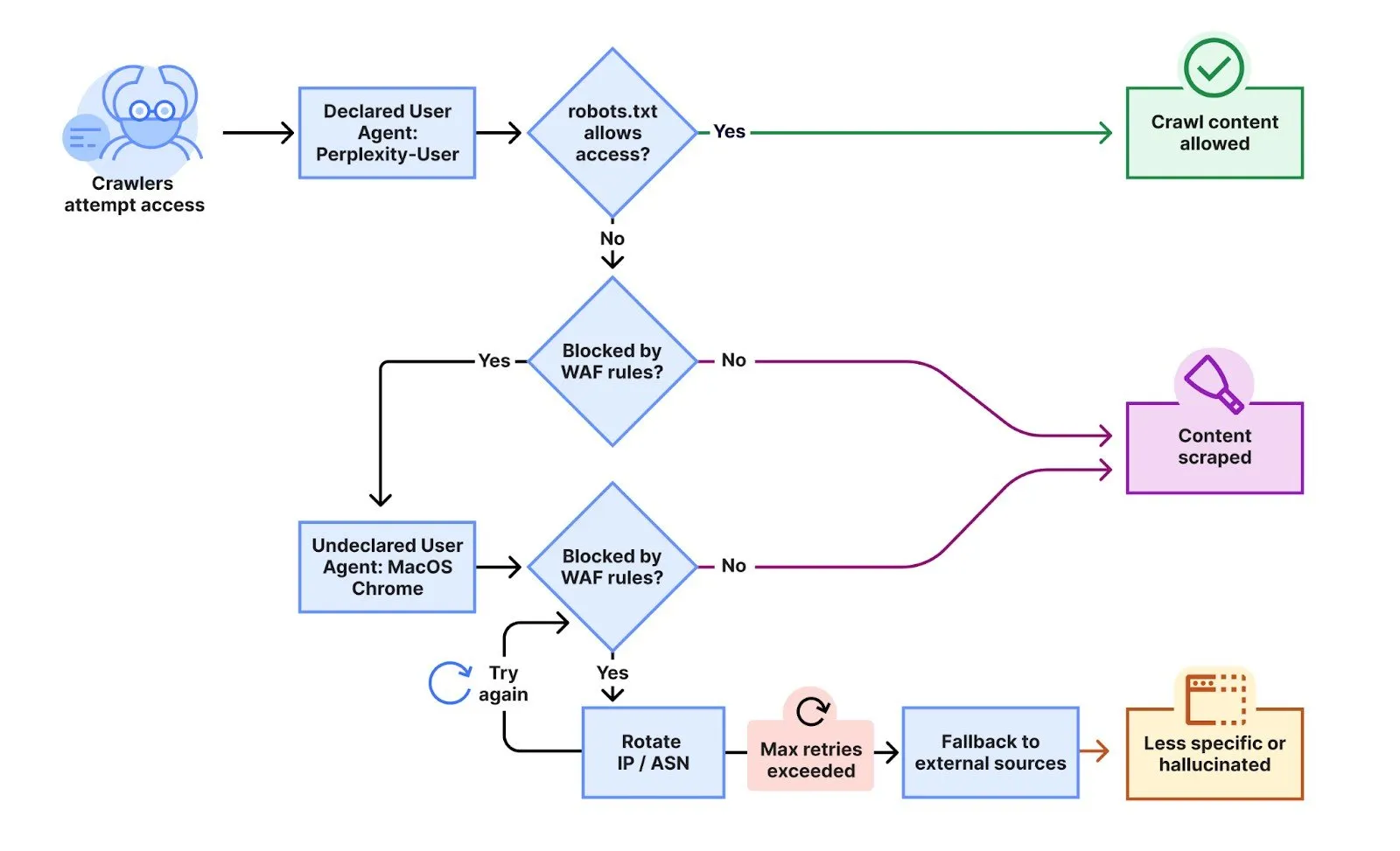
El reciente conflicto estalló después de que los clientes de Cloudflare se quejaron de que la perplejidad todavía estaba raspando sus sitios a pesar de implementar ambos robots. Directivas de TXT y reglas específicas de firewall para bloquear a los rastreadores declarados de la compañía de IA. Los ingenieros de Cloudflare Gabriel Corral, Vaibhav Singhal, Brian Mitchell y Reid Tatoris confirmaron en las pruebas que “los rastreadores de Perplexity estaban siendo bloqueados en las páginas específicas en cuestión”.
Para probar el comportamiento de Perplexity, Cloudflare creó múltiples dominios recién comprados con robots restrictivos.txt archivos que prohibieron todo el acceso automatizado. “Realizamos un experimento al consultar la IA de perplejidad con preguntas sobre estos dominios, y la perplejidad descubierta todavía proporcionaba información detallada sobre el contenido exacto alojado en cada uno de estos dominios restringidos”.
Lo que sucedió después los sorprendió. En lugar de respetar los bloques, la perplejidad parecía cambiar las tácticas. “Observamos que los usos de perplejidad no solo su agente de usuario declarado, sino también un navegador genérico destinado a hacerse pasar por Google Chrome en macOS cuando su rastreador declarado fue bloqueado”, escribieron los ingenieros.
Fuente: CloudFlare
Los rastreadores sigilosos emplearon técnicas de evasión sofisticadas. “Este rastreador no declarado utilizó múltiples IPS que no figuran en el rango de IP oficial de Perplexity, y giraría a través de estos IP en respuesta a los robots restrictivos. Política de txt y bloquea desde Cloudflare. Además de las IP giratorias, observamos solicitudes provenientes de diferentes ASN en intentos para evadir aún más los bloques de sitios web”.
Según Cloudflare, los rastreadores “declarados” de Perplexity, los que son fácilmente identificables, generan 20-25 millones de solicitudes diariamente, mientras que los rastreadores sigilosos no declarados, aquellos que dependen de tácticas sombrías para ocultar su propósito, agregan otras 3-6 millones de solicitudes por día. “Esta actividad se observó a través de decenas de miles de dominios y millones de solicitudes por día”.
La compañía no respondió a DescifrarSolicitud de comentarios. Un portavoz desestimó las acusaciones a TechCrunch como nada más que un “argumento de venta” de Cloudflare.
El CEO de Cloudflare, Matthew Prince, ha expresado lo que ve como la extracción insostenible de contenido web de las compañías de IA. “Las referencias de tráfico de búsqueda se han desplomado a medida que las personas confían cada vez más en resúmenes de IA”. En julio, reveló proporciones devastadoras: mientras que Google envía un visitante por cada 18 páginas que se arrastra, las compañías de IA son mucho peores. La relación de OpenAI se deterioró de 250 a 1 hace seis meses a 1,500 a 1 hoy. Los números de Anthrope son aún más extremos, saltando de 6,000 a 1 a 60,000 a 1 en el mismo período.

Fuente: CloudFlare
Esto llevó a Cloudflare a lanzar lo que llama “Día de la Independencia de Contenido”, al bloquear los rastreadores de IA para todos los nuevos dominios, convirtiéndose en la vigilante de facto que protege a los creadores de contenido de las amenazas de los molestos rastreadores de IA.
Como Descifrar previamente informado, más de un millón de sitios web ya habían optado por el bloqueo desde el otoño pasado, con los principales editores, incluidos los Prensa asociada, Tiempo, El atlántico, BuzzfeedReddit, Quora y Universal Music Group se unen al movimiento.
“Existen preferencias claras de que los rastreadores deben ser transparentes, cumplir un propósito claro, realizar una actividad específica y, lo más importante, seguir las directivas y preferencias del sitio web”, declaró Cloudflare. La compañía contrasta el comportamiento de Perplexity con OpenAI, que dijo que respeta correctamente los archivos de robots.
La respuesta de Cloudflare incluye tanto medidas técnicas inmediatas como iniciativas a largo plazo. La compañía ha implementado coincidencias de firma para el rastreador Stealth en sus reglas administradas, disponibles para todos los clientes, incluidos los usuarios gratuitos. También está desarrollando herramientas como un “laberinto de IA”, que atrapa bots no conformes en laberintos de contenido falso, y un mercado de “pago por tren” que permitiría a los editores cobrar a las compañías de IA por el acceso a su contenido.